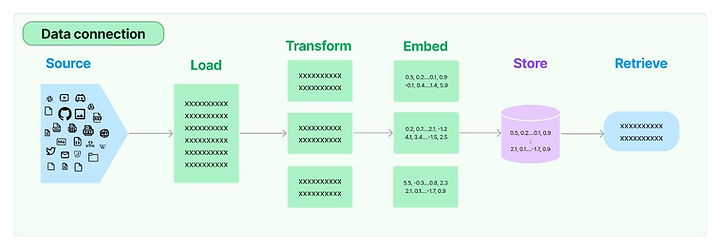
向量資料庫與檢索
內嵌可將所有類型的資料編碼為向量,以擷取資產含義和內容。這讓我們能夠搜尋相鄰的資料點,藉此來尋找類似的資產。向量搜尋方法可帶來獨特的體驗,例如使用智慧型手機拍照和搜尋類似影像。
向量資料庫提供以高維度點存放和擷取向量的功能。向量資料庫還具有額外的功能,可供高效快速地查詢 N 維空間中的最近鄰。通常採用 k-最近鄰 (k-NN) 索引技術,並使用 Hierarchical Navigable Small World (HNSW) 和 Inverted File Index (IVF) 之類的演算法進行建置。向量資料庫還提供額外功能,例如資料管理、容錯、身分驗證和存取控制,以及查詢引擎。

Conversational Retrieval Chain
我們有一個檢索器來從向量儲存中取得與使用者輸入相關的文件。對於會話檢索鏈,我們必須讓檢索器取得不僅與使用者輸入相關而且與聊天歷史記錄相關的文件。因此,檢索器不僅需要基於使用者輸入進行查詢,還需要基於聊天記錄中的相關文件進行查詢。為此,我們向 LLM 提供聊天歷史記錄和使用者輸入,並要求其派生搜尋查詢,以便檢索器從向量儲存中取得相關資料。
這是因為語言模型裡面沒有關於我們的資料/私人資料,所以它無法回答這類不在模型裡的問題,跟 ChatGPT 給我們的那種自然對話體驗全然不同。
為了做到跟 ChatGPT 相似的體驗,我們必須為語言模型做一些額外的步驟,簡化後的步驟如下:
1
讓它能夠讀取語言模型以外的資料
2
將語言模型以外的資料轉換為 embedding
3
將第 2 步所產生的 embedding 存起來
4
告訴語言模型要用什麼方式檢索這些資料,最簡單方式是相似度比較
1.收集資料:準備與應用場景相關的問答對或文本資料集。資料可以來自文檔、網頁或手工編輯的問答。
2.清理與處理資料:移除無用或重複的內容。將資料轉換為模型接受的格式(例如 JSON 格式的問答對)。
3.生成嵌入:使用嵌入生成器(如 OpenAIEmbeddings)將文本轉換為向量表示。
4.構建向量資料庫:使用工具(如 Chroma 或 FAISS)創建一個向量資料庫,儲存嵌入。
5.微調語言模型:如果需要更精確的回答,可通過 OpenAI 提供的微調功能(Fine-tuning)在 GPT 模型上進行自定義訓練,使用收集的數據集進一步強化模型。
AI 模型的訓練
模型的優化與部署
1.模型優化:微調模型,增強其在特定領域的表現。減少回應時延,例如通過調整最大 Token 或優化檢索過程。
2.部署模型:將已完成訓練或微調的模型部署到伺服器上。
維護向量資料庫與檢索功能。

成果展示




程式碼的詳細解釋
(包括架構和功能模組)
LINE Messaging API:用於接收使用者訊息並回覆。
LangChain:負責構建檢索增強生成(RAG)架構的處理流程。
Chroma:作為持久化向量資料庫,用於語義檢索。
OpenAI ChatGPT:生成自然語言回應。
Flask:作為 Web 服務框架,處理 HTTP 請求。
程式碼功能解析
1. LINE 設定
LINE_CHANNEL_ACCESS_TOKEN = os.getenv("LINE_CHANNEL_ACCESS_TOKEN", "YOUR_ACCESS_TOKEN")
LINE_CHANNEL_SECRET = os.getenv("LINE_CHANNEL_SECRET", "YOUR_SECRET")
功能:設定 LINE 平台所需的 Channel Access Token 和 Channel Secret。
目的:驗證來自 LINE 的請求,並授權回應訊息。
2. 環境變數與 OpenAI API 金鑰
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
功能:設置 OpenAI 的 API 金鑰,用於授權 ChatGPT 語言模型的使用。
目的:確保應用能夠調用 OpenAI 的服務。
3. 向量資料庫的初始化
persist_directory = "chroma_vectorstore"
if os.path.exists(persist_directory):
vectorstore = Chroma(persist_directory=persist_directory, embedding_function=OpenAIEmbeddings())
else:
logging.error("向量庫不存在,請檢查是否已儲存。")
exit(1)
功能:
檢查是否有現有的向量資料庫(chroma_vectorstore 資料夾)。
若存在,載入向量資料庫;若不存在,記錄錯誤並退出程式。
目的:透過向量資料庫管理和檢索語義嵌入,支援與聊天機器人相關的知識檢索功能。
4. Conversational Retrieval Chain 創建
qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0, max_tokens=500),
vectorstore.as_retriever()
)
功能:
創建一個基於 ChatGPT 和向量資料庫的檢索生成鏈條。
ChatOpenAI:設定生成模型的溫度和回應字數限制。
vectorstore.as_retriever():將向量資料庫作為檢索器,為生成模型提供上下文資料。
目的:實現「檢索增強生成」(RAG) 功能,將語義檢索和自然語言生成相結合。
5. 聊天歷史管理
chat_history = []
功能:用於儲存與管理使用者和機器之間的多輪對話記錄。
目的:支援多輪對話功能,使系統能夠基於歷史上下文生成連貫回答。
6. 回應 LINE 訊息
def reply_message(reply_token, message):
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {LINE_CHANNEL_ACCESS_TOKEN}'
}
body = {
'replyToken': reply_token,
'messages': [{'type': 'text', 'text': message}]
}
requests.post('https://api.line.me/v2/bot/message/reply', headers=headers, data=json.dumps(body))
功能:
接收 LINE 的回應 token 和訊息內容,並通過 LINE Messaging API 將回應發送回去。
目的:完成訊息的雙向交互,使機器人能回覆用戶。
7. Webhook 接收與處理
@app.route("/callback", methods=['POST'])
def callback():
body = request.json
events = body.get('events', [])
for event in events:
if event['type'] == 'message' and event['message']['type'] == 'text':
user_message = event['message']['text']
reply_token = event['replyToken']
功能:
接收 LINE 平台發送的 Webhook 請求,處理使用者的文字訊息。
提取使用者的輸入內容和回應 token。
目的:解析 LINE 的訊息事件,為後續處理做準備。
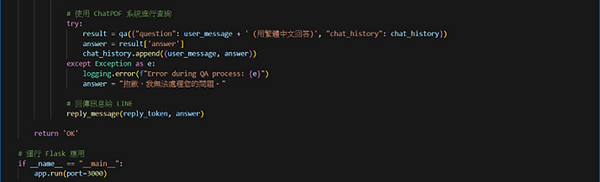
8. 生成回應
try:
result = qa({"question": user_message + ' (用繁體中文回答)', "chat_history": chat_history})
answer = result['answer']
chat_history.append((user_message, answer))
except Exception as e:
logging.error(f"Error during QA process: {e}")
answer = "抱歉,我無法處理您的問題。"
功能:
使用 ConversationalRetrievalChain,基於用戶輸入(user_message)與對話歷史(chat_history),生成上下文相關的回應。
若發生錯誤,記錄錯誤資訊並生成預設錯誤回應。
目的:透過 RAG 架構提供智慧回應,並處理潛在錯誤。
9. 回應使用者
reply_message(reply_token, answer)
功能:透過 LINE API 將生成的回應發送回使用者。
目的:完成機器人回應功能。
10. 啟動 Flask 應用
if __name__ == "__main__":
app.run(port=3000)
功能:啟動 Flask 伺服器,監聽 HTTP 請求(預設監聽在本地端 3000 埠)。
目的:運行應用,準備接受來自 LINE 的 Webhook 請求。
完整流程:
使用者訊息:使用者在 LINE 發送訊息。
Webhook 接收:Flask 接收 LINE 發送的 Webhook 請求。
檢索與生成:
使用者輸入被傳遞給 ConversationalRetrievalChain。
系統檢索向量資料庫中的相關內容,輔助生成回答。
回應訊息:生成的回應通過 LINE API 回傳給使用者。
關鍵技術點:
LINE Messaging API:處理訊息的傳輸與回應。
Chroma 向量資料庫:高效檢索資料,支援 RAG 架構。
LangChain:負責檢索與生成邏輯。
Flask:處理 HTTP 請求,作為 Web 應用伺服器。
OpenAI GPT:生成自然語言回答。
成果比較
1. 架構比較
ChatGPT:僅用語言模型
ChatPDF:檢索功能,使用 Chroma 向量資料庫,基於語義進行檢索,提供相關上下文作為回答的輔助資料,無檢索功能,僅依賴內部模型的記憶與上下文理解。生成功能, 利用 OpenAI 的 ChatGPT 模型生成回答,但回答基於檢索結果,直接使用模型生成回答,不依賴外部資料檢索。上下文管理,使用 ConversationalRetrievalChain,結合檢索上下文和聊天歷史生成更準確的答案,能處理有限的上下文(最大 token 限制),無法持久化聊天歷史。
資料來源, 依靠向量資料庫(Chroma)作為外部知識基礎,完全依賴模型內部的預訓練知識和對當前輸入的理解。
2. 功能比較-檢索能力
ChatGPT:無檢索功能,無法動態查詢外部資料。如果問題涉及未知領域,可能會產生錯誤回答。
ChatPDF:可以檢索外部資料庫中的相關內容,解決 ChatGPT 的內建知識有限性問題。特別是在處理企業內部知識(如文檔、產品資料)或特定領域的問題時具有優勢。
回答準確性
ChatGPT:回答依賴於內部模型的預訓練知識,如果問題不在模型的知識範圍內,可能會給出模糊甚至錯誤的答案。
ChatPDF:回答基於檢索的上下文資料,回答的準確性和可靠性更高,特別是對於需要特定資料支撐的問題。
多輪對話能力
ChatGPT:在有限的 token 範圍內支持多輪對話,但無法記憶對話歷史,會隨 token 長度增加而丟失早期上下文。
ChatPDF:儲存對話歷史,支持基於歷史上下文進行多輪對話,並利用檢索結果進一步輔助回答。
擴展性
ChatGPT:模型知識是靜態的,無法隨應用需求動態擴充。
ChatPDF:可以動態更新向量資料庫,加入新的知識點,隨時擴展應用能力。
3. 技術實現的差異
ChatGPT:單一模型應用
ChatPDF:語義檢索技術, 使用 Chroma 向量資料庫進行語義相似性檢索,輔助回答生成,無語義檢索功能,對話生成技術, 利用 OpenAI ChatGPT 生成答案,但基於檢索的資料進行輔助生成, 完全依賴語言模型進行生成,聊天歷史管理, 使用 ConversationalRetrievalChain 管理聊天歷史,支持上下文處理, 僅限於 token 範圍內的上下文處理,資料來源更新, 向量資料庫可以隨時更新,適應新需求,模型知識固定,無法更新。
4. 使用場景比較
ChatGPT:單一模型應用
ChatPDF:企業內部問答, 非常適合,能檢索內部文件,提供準確回答。, 無法檢索內部文件,依賴於模型知識。一般知識性對話, 可以回答,但更偏向於專業知識的準確性需求,非常適合,生成流暢的自然語言回答。需要動態更新資料的應用, 能輕鬆更新資料庫,保持系統回答的準確性,需要重新訓練模型,成本較高,無外部依賴的簡單應用, 系統較複雜,需依賴檢索資料。, 適合,模型即插即用。
5. 優缺點比較
ChatGPT:
優點:簡單易用,即插即用,生成自然語言能力強,適合開放式對話。
缺點:
缺乏檢索功能,無法處理特定領域的專業問題,無法動態更新知識,受限於訓練時的知識。
ChatPDF:
優點:
能處理結構化或專業性強的問題,具備可擴展性,可以隨時更新資料庫,結合檢索與生成,回答準確性更高。
缺點:需要維護 Chroma 向量資料庫,部署相對複雜,回應速度可能受檢索和生成過程影響。